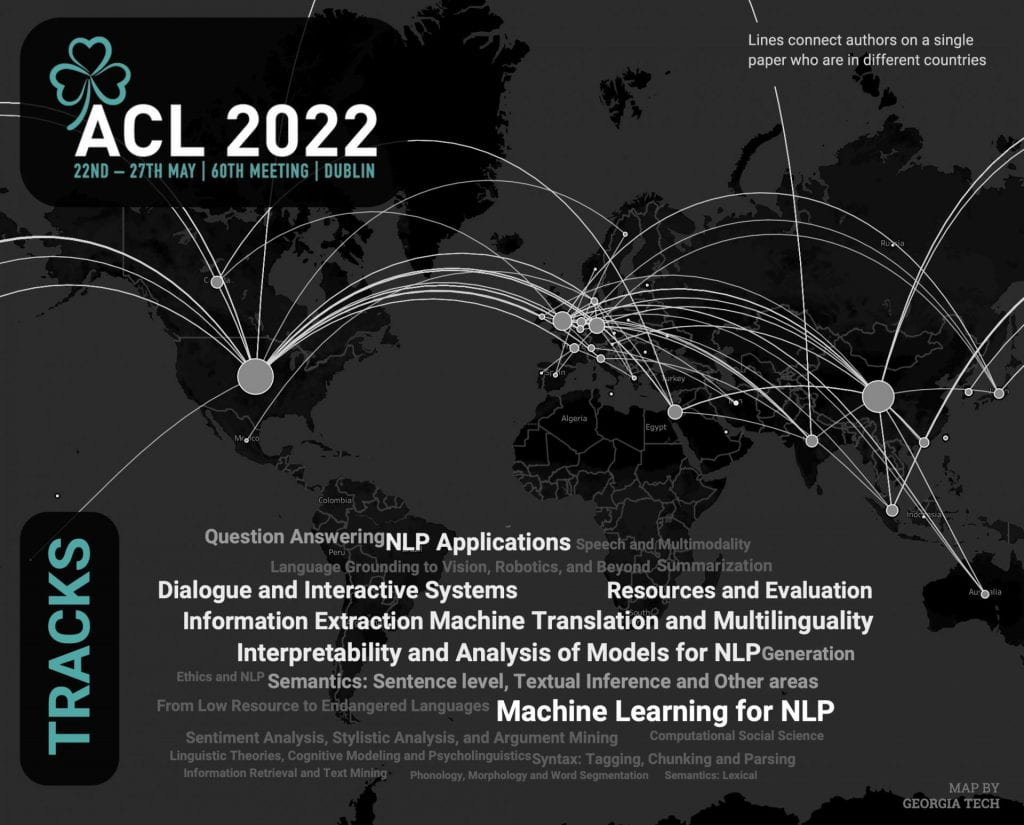
Georgia Tech experts in natural language processing (NLP) — a field that involves building machines that can “understand” human language — will present their latest research May 22 – 27, 2022, at the 60th Meeting of the Association for Computational Linguistics. ACL is the premier international scientific and professional society for people working on computational problems involving human language.

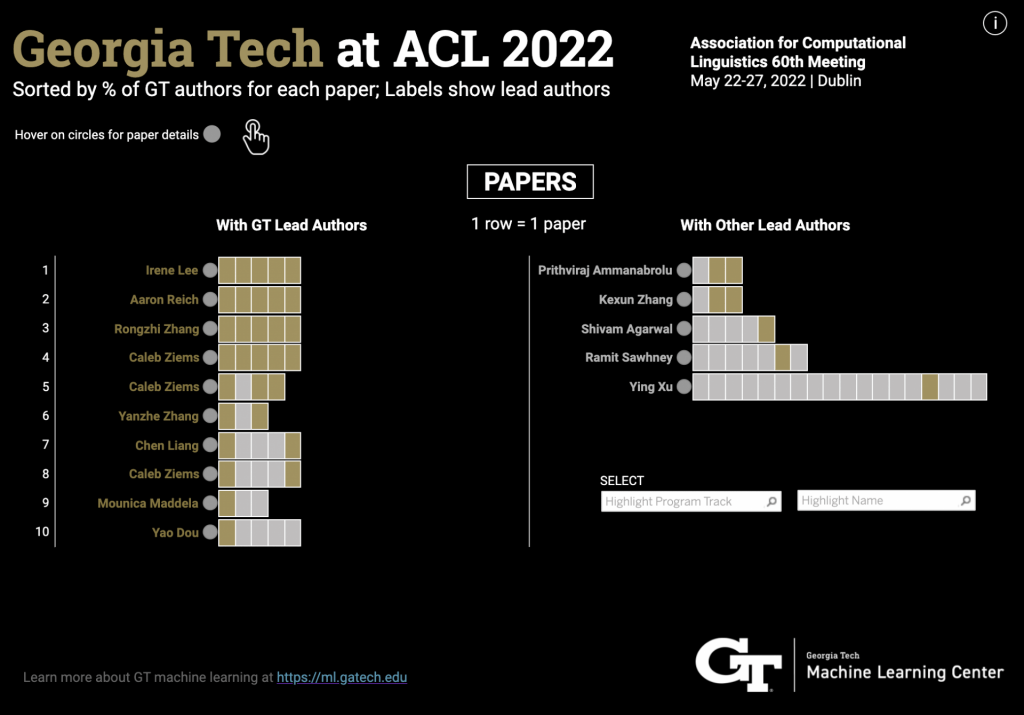
(size of text on images approximates the frequency of words in selected research paper by each author)

I am very excited to participate in ACL 2022 in Dublin – the first in-person NLP conference in my career as a faculty. With several SALTers, we will be presenting a set of research studies ranging from dialect inclusive NLP to continual learning and positive reframing. More importantly, our undergraduate team will talk about their humor generation chatbot during the Student Research Workshop. I am super proud of the work our students will be sharing at ACL; most of these works center nicely around the theme of Socially Aware NLP, the study and development of language technologies from a social perspective. We hope this line of work can inspire more research into the social aspects of NLP and push the boundary of what we can achieve as a research field. Look forward to meeting everyone at ACL 2022!
Diyi Yang, Assistant Professor, School of Interactive Computing

Natural Language Processing (NLP) systems have solved many standard tasks with an accuracy that can beat even humans. Chatbots are also coming increasingly closer to human levels of conversation. Still, we find these models are often brittle and, for the most part, socially unintelligent. Natural Language Understanding (NLU) systems have a very hard time with irregularities or variation in language, and conversational agents lack the social competence to navigate emotionally challenging or morally ambiguous conversations. We should recognize these weaknesses as opportunities for so much more exciting work to come.
Caleb Ziems, PhD Student, Computer Science
RESEARCH IN FOCUS

Chatbots Could Help You Focus on Positive Language While Keeping Your Original Meaning
By Caleb Ziems
When we are stressed or struggling with adversity, it is easy to slip into certain unhealthy patterns of thought called cognitive distortions. These distorted beliefs often exaggerate or over-emphasize the negative aspects of our situation that we can’t really control, making us feel defeated and hopeless. Psychologists have designed a special kind of therapy for treating depression and anxiety, and it works to overturn these cognitive distortions. If we instead focus on things like our own strengths, our progress in overcoming adversity, and capacity for growth and change, we can break free from many of the negative patterns of thought that weigh us down.
Recent work from Prof. Diyi Yang and the SALT Lab at Georgia Tech shows how we can use Natural Language Processing to teach us how to positively reframe our own thoughts. Their recent paper describes a system that takes a negative sentence and automatically rewrites it with a more positive perspective. The new sentences sound more genuine because they can stay true to the meaning of the original sentence.
In this way, machines could someday help us regulate our emotions by suggesting alternative ways of expressing ourselves in stressful or challenging situations. Overall, machine assistance is significantly cheaper and more accessible than professional therapy, and it may provide a complementary resource for online mental health support.
Overall, positive reframing is a useful skill for both humans and human-assisting chatbots. Soon, you may be talking with a friendly chatbot who can help you practice self-care, set goals, and stay more positive in your day-to-day life.

Large language models, which have reached several billion parameters, have demonstrated their powerful generalizability to downstream applications. However, such improvement comes at the expense of high inference latency and memory cost. My current research focuses on improving the parameter efficiency and generalizability of large language models by developing model compression approaches to remove redundant parameters and developing optimization and regularization strategies to utilize all parameters fully.
I am thrilled that this field has drawn more attention as the model has become larger rapidly. I believe the most exciting research is yet to come, making large models accessible to ordinary people’s lives.
Chen Liang, PhD Student, Machine Learning

We are seeing incredibly powerful language modeling techniques capable of language production. On the surface, these large language models look really great. But when we dig in, there is something that is always slightly “off”—they are “fancy babblers”. One of the reasons for this is that language models are not grounded.
Humans have shared experiences from living and acting in the real world, and we can make reference to these shared experiences to make communication more effective and efficient. Language models trained on data do not share our experiences. By helping these models connect their data-driven understanding of language to action and experience in real and virtual worlds, we may be able to tamp down on the unwanted and unexpected language generation.
Mark Riedl, Professor, School of Interactive Computing

Weakly-supervised learning (WSL) has shown promising results in addressing label scarcity on many NLP tasks, including text classification, relation extraction, and sequence tagging. In weakly-supervised learning, the labeling rules can be matched with unlabeled data to create large-scale weakly labeled data, allowing for training weakly-supervised models with much lower annotation cost. However, manually designing a comprehensive, high-quality labeling rule set is tedious and difficult, thus state-of-the-art WSL methods still underperform fully-supervised methods by significant gaps on many NLP tasks.
To bridge the gap between weakly-supervised and fully-supervised approaches, we study the problem of iteratively and automatically discovering novel labeling rules from data to improve WSL models. Recent work from Dr. Chao Zhang’s lab shows how humans collaborate with machines to discover complementary rules and refine the WSL model continuously.
Rongzhi Zhang, PhD Student, Machine Learning

Explore the Complete ACL Program in Charts📊